As mentioned in the earlier blog, First Steps towards Big Data, analyzing and understanding the use cases and data is one of the founding steps in overall big data strategy. This blog will look at various ways we can perform such analysis.
Even before we start, there is a pitfall that we should make sure we are avoiding. –
In determining the strategy, it is highly essential to remember that the Big Data analysis is only an efficient supporting tool for the overall company strategy. While it may validate conclusions and answer multiple questions — and in rare cases, dramatically affect the overall direction in which the company is going — it cannot be the primary goal of company strategy. The primary goal will always be something like “market driven production”, “demographic based sales strategy” etc where big data analysis
will act as a supporting tool towards these goals.
With this in mind, we can start looking at what use cases and data the company has. There are two sides to this problem:
- Analysis Goals
- Data Patterns
As shown in the figure, both these factors will influence each other greatly.
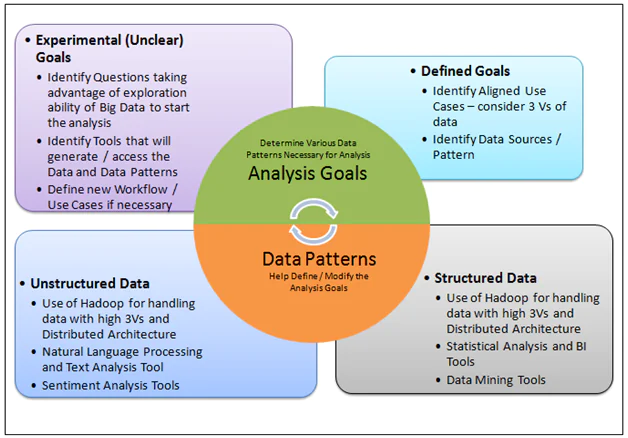
Analysis Goal Definition
A lot will depend on the analysis goal definition. In case, the company is sure of what they are looking for, statistical analysis of historical and real-time structured data can be the order of the day.
However, in case the company wants to experiment with various analysis and findings (and does have a very vague goal definition at best) we will need to start with multiple questions as input to experimentation. Tools that conduct polls and surveys, find trends using textual analysis of social data etc will help get a wide range of information for further decision making.
Data Pattern
On the other side of the spectrum, the overall data can be divided into two types:
- Transactional data
- Non Transactional data
Transactional data typically consists of structured data. It can be historical data, user data generated with day-to-day use, data generated by various functions of the organization etc. This is the data that we store in various database tables, and essentially has a predictable structure. The use cases here will deal majorly with the volume of the data as well as the Distributed Architecture of data.
Non transactional data on the other hand is the data that is coming in through various social media interactions. It can make use of various Social Networking Portals as well as emails, SMS etc. Another example of such data can be various logs generated regularly. The Non transactional data is mainly textual, with possible images and audio associated with the text. Typically this data does not conform to a standard schema.
Due to enormous volume of the data, as well as variety and velocity of data accumulation, use of Big Data Platforms like Hadoop will be necessary. These different data types need to be handled through different tools and mechanisms. Typically the transactional data may use business analysis and data mining tools and the non transactional data will need sentiment analysis and natural language processing / crowd sourcing tools.
In conclusion, classifying the use cases as well as Data Source and Patterns will provide us a high level idea of the workflow, platforms and tools necessary for Big Data analysis. This will be the foundation of Big Data Strategy.
Next blog will look at various preparation steps and road block in determining the big data strategy.