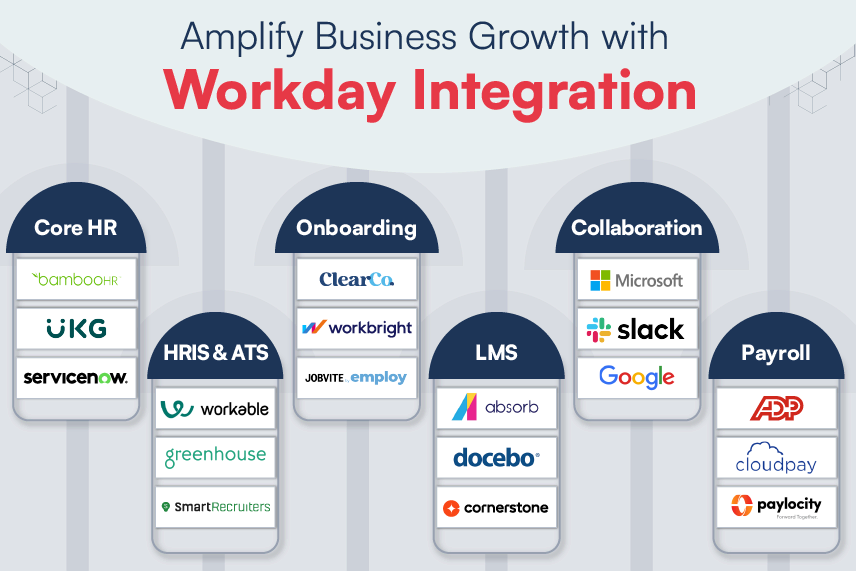
There is no shortage of training content for employees. However, quick access to the right information is the challenge. Traditionally, the L&D departments spend significant time on instructor-led training and aggregating and buying third-party training content. However, courses on LMS aren’t sufficient for employee training anymore. Other learning avenues, like on-the-job training, personalized training, micro-learning, and data or event-driven training programs are equally important. Employees today learn from content spread across internal and external systems including intranets, MooC platforms, LMS, social media platforms, external training content providers, document management systems, collaboration platforms, and even forums, Q&A portals, email and messenger/ chat platforms. This scenario presents newer opportunities to curate content from multiple sources, classify it for appropriate use cases and add it to the enterprise knowledge base. Such an arrangement is necessary to enable employees to discover the right content at the right point in time.
According to Forrester Research, more than half (54%) of enterprise workers waste their time due to an interruption in work to get access to the right information, insights, and answers. Another study from IDC suggests that workers within an enterprise (1000+ employees) waste about $5.7 million annually trying to find the right information. Today’s employees are far more eager to learn from their peers, managers and even popular external sources (Wikis, Q&A sites, forums, social media, etc) and not necessarily depend on the corporate trainer or expert-created content. Additionally, rapid changes in various industries demand employees to constantly learn and upskill themselves to perform satisfactorily. Formal training programs are not sufficient to meet such demands and there is a strong unmet need to leverage content residing on various learning and collaboration platforms to address the content discovery problem within an enterprise.
Traditionally most of the information/ knowledge base is classified into various categories for the purpose of fast retrieval. It was an easier problem to address when most of the data was structured and knowledge was centralized. Today we face unstructured data and multiple information silos due to several departments and disparate applications used within an enterprise. This data landscape has made artificial intelligence based curating indispensable for efficient content discovery.
AI-based content curation and classification allow enterprises to harness knowledge lying across portals, forums, customer support chats, emails, and various community software and knowledge management platforms. Following are some of the real world use cases that can benefit immensely from AI assisted curation.
New Employee Onboarding Training
Onboarding training is about answering commonly asked questions and recommending appropriate training resources for performing common tasks in the first few weeks on the job. This can be accomplished by anonymizing and classifying past employee’s content like their email, chat, and notes. It can then be curated, using machine learning, into FAQ, and categorized as the learning content for the relevant job roles. This approach of onboarding would lead to a significant saving in time and money compared to personalized training.
Enterprise Knowledge Base
Redundant, outdated, and trivial data makes it hard to get to the right information even with powerful search tools. Classifying and updating knowledge base in real time is, therefore, a necessity. One also needs the ability to tap into disparate sources of data, i.e. various departments and applications. One needs to go beyond usual tagging and categorization and refactor the knowledge base to serve next-generation cognitive applications like the interactive virtual assistant, context and intent-based search, and recommendation engines.
FAQ or Chatbot training
Training the chatbot and developing FAQ are labor-intensive processes. Moreover, such training data tend to become obsolete quickly. It is thus imperative to automatically create the FAQ and train the chatbot with new knowledge on a regular basis. For example, new customer chats and emails can be curated by machine learning algorithms to classify support requests and to update FAQ. This information, in turn, needs to be used to train the chatbot.
L&D department spending has risen consistently over years. However, even today, a disproportionately small amount is spent on curating information compared to the investment in sourcing externally produced content. IDG survey suggests that enterprise organizations are investing heavily ($13.8 million) in data-driven initiatives where employee training is a major beneficiary. This leads us to believe that content curation holds great promise as it can effectively harness enterprise knowledge base spread across disparate systems by leveraging innovative AI/ ML tools.
If you are an LMS, knowledge-base, or collaboration software provider, do let us know your thoughts and ideas on this strategy.